









सामग्री
सध्या, मायक्रोसॉफ्ट एक्सेलमध्ये फंक्शन विझार्ड विंडो – बटणाद्वारे जवळपास पाचशे वर्कशीट फंक्शन्स उपलब्ध आहेत fx फॉर्म्युला बारमध्ये. हा एक अतिशय सभ्य संच आहे, परंतु, तरीही, जवळजवळ प्रत्येक वापरकर्त्याला लवकरच किंवा नंतर अशा परिस्थितीचा सामना करावा लागतो जेथे या सूचीमध्ये त्याला आवश्यक असलेले कार्य नसते - फक्त ते Excel मध्ये नसल्यामुळे.
आत्तापर्यंत, या समस्येचे निराकरण करण्याचा एकमेव मार्ग मॅक्रो होता, म्हणजे व्हिज्युअल बेसिकमध्ये आपले स्वतःचे वापरकर्ता-परिभाषित कार्य (UDF = वापरकर्ता परिभाषित कार्य) लिहिणे, ज्यासाठी योग्य प्रोग्रामिंग कौशल्ये आवश्यक आहेत आणि काही वेळा ते सोपे नसते. तथापि, नवीनतम Office 365 अद्यतनांसह, परिस्थिती अधिक चांगल्यासाठी बदलली आहे - एक्सेलमध्ये एक विशेष "रॅपर" कार्य जोडले गेले आहे. LAMBDA. त्याच्या मदतीने, आपले स्वतःचे कार्य तयार करण्याचे कार्य आता सहजपणे आणि सुंदरपणे सोडवले जाते.
पुढील उदाहरणात त्याच्या वापराचे तत्त्व पाहू.
तुम्हाला माहीत असेलच की, एक्सेलमध्ये अनेक तारीख पार्सिंग फंक्शन्स आहेत जी तुम्हाला दिलेल्या तारखेसाठी दिवस, महिना, आठवडा आणि वर्षांची संख्या निर्धारित करण्यास अनुमती देतात. परंतु काही कारणास्तव असे कोणतेही कार्य नाही जे तिमाहीची संख्या निर्धारित करते, ज्याची देखील आवश्यकता असते, बरोबर? चला ही कमतरता दूर करूया आणि तयार करूया LAMBDA या समस्येचे निराकरण करण्यासाठी स्वतःचे नवीन कार्य.
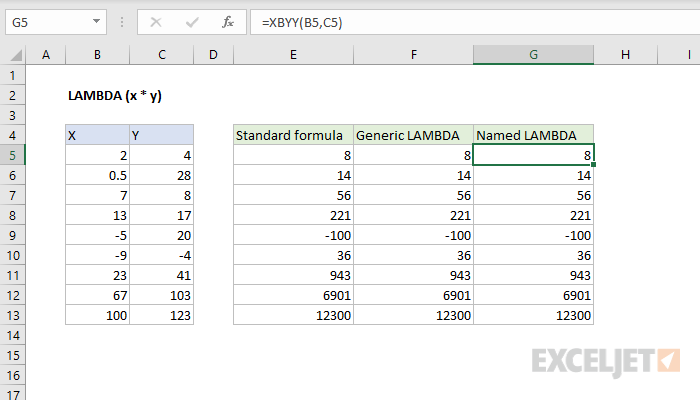
पायरी 1. सूत्र लिहा
चला या वस्तुस्थितीपासून सुरुवात करूया की नेहमीच्या पद्धतीने आपण पत्रक सेलमध्ये एक सूत्र लिहू जे आपल्याला आवश्यक असलेल्या गोष्टींची गणना करते. तिमाही क्रमांकाच्या बाबतीत, हे केले जाऊ शकते, उदाहरणार्थ, यासारखे:

पायरी 2. LAMBDA मध्ये गुंडाळणे आणि चाचणी करणे
आता नवीन LAMBDA फंक्शन लागू करण्याची आणि त्यात आमचे सूत्र गुंडाळण्याची वेळ आली आहे. फंक्शन सिंटॅक्स खालीलप्रमाणे आहे:
=लॅम्ब्डा(व्हेरिएबल1; व्हेरिएबल2; … व्हेरिएबलN ; अभिव्यक्ती)
जिथे एक किंवा अधिक व्हेरिएबल्सची नावे प्रथम सूचीबद्ध केली जातात आणि शेवटचा युक्तिवाद नेहमी एक सूत्र किंवा गणना केलेला अभिव्यक्ती असतो जो त्यांचा वापर करतो. व्हेरिएबल नावे सेल पत्त्यांसारखी दिसू नयेत आणि त्यात ठिपके नसावेत.
आमच्या बाबतीत, फक्त एक व्हेरिएबल असेल - ज्या तारखेसाठी आम्ही तिमाही क्रमांकाची गणना करतो. त्यासाठी व्हेरिएबलला कॉल करू, म्हणा, डी. मग आपले सूत्र फंक्शनमध्ये गुंडाळणे LAMBDA आणि मूळ सेल A2 चा पत्ता काल्पनिक व्हेरिएबल नावाने बदलून, आम्हाला मिळते:

कृपया लक्षात घ्या की अशा परिवर्तनानंतर, आमचे सूत्र (खरं तर, बरोबर!) त्रुटी निर्माण करू लागले, कारण आता सेल A2 मधील मूळ तारीख त्यात हस्तांतरित केलेली नाही. चाचणी आणि आत्मविश्वासासाठी, फंक्शन नंतर जोडून तुम्ही त्यात युक्तिवाद पास करू शकता LAMBDA कंसात:

पायरी 3. नाव तयार करा
आता सोप्या आणि मजेदार भागासाठी. आम्ही उघडतो नाव व्यवस्थापक टॅब सुत्र (सूत्र - नाव व्यवस्थापक) आणि बटणासह नवीन नाव तयार करा तयार करा (तयार करा). समोर या आणि आमच्या भविष्यातील कार्यासाठी नाव प्रविष्ट करा (उदाहरणार्थ, नोमकवर्तला), आणि शेतात दुवा (संदर्भ) फॉर्म्युला बारमधून काळजीपूर्वक कॉपी करा आणि आमचे फंक्शन पेस्ट करा LAMBDA, फक्त शेवटच्या युक्तिवादाशिवाय (A2):

सर्व काही. वर क्लिक केल्यानंतर OK तयार केलेले फंक्शन या वर्कबुकच्या कोणत्याही शीटवरील कोणत्याही सेलमध्ये वापरले जाऊ शकते:

इतर पुस्तकांमध्ये वापरा
LAMBDA आणि डायनॅमिक अॅरे
फंक्शनसह सानुकूल कार्ये तयार केली जातात LAMBDA नवीन डायनॅमिक अॅरे आणि त्यांच्या फंक्शन्ससह कार्यास यशस्वीरित्या समर्थन देते (FILTER, UNIK, गट) 2020 मध्ये Microsoft Excel मध्ये जोडले.
समजा आम्हाला एक नवीन वापरकर्ता-परिभाषित फंक्शन तयार करायचे आहे जे दोन सूचींची तुलना करेल आणि त्यांच्यातील फरक परत करेल - पहिल्या सूचीतील ते घटक जे दुसऱ्यामध्ये नाहीत. जीवनाचे काम, नाही का? पूर्वी, यासाठी ते एकतर फंक्शन्स वापरत असत व्हीपीआर (VLOOKUP), किंवा PivotTables, किंवा Power Query क्वेरी. आता आपण एका सूत्रासह करू शकता:

इंग्रजी आवृत्तीमध्ये ते असेल:
=LAMBDA(a;b;ФИЛЬТР(a;СЧЁТЕСЛИ(b;a)=0))(A1:A6;C1:C10)
येथे कार्य COUNTIF दुसऱ्या यादीतील प्रत्येक घटकाच्या घटनांची संख्या आणि नंतर फंक्शन मोजते FILTER त्यांच्यापैकी फक्त त्यांनाच निवडते ज्यांच्याकडे या घटना घडल्या नाहीत. मध्ये ही रचना गुंडाळून LAMBDA आणि त्यावर आधारित नामांकित श्रेणी तयार करणे, उदाहरणार्थ, शोध वितरण - आम्हाला एक सोयीस्कर फंक्शन मिळेल जे डायनॅमिक अॅरेच्या स्वरूपात दोन सूचींची तुलना केल्यावर परिणाम मिळवून देते:

स्त्रोत डेटा सामान्य नसल्यास, परंतु "स्मार्ट" सारण्या असल्यास, आमचे कार्य देखील समस्यांशिवाय सामना करेल:

दुसरे उदाहरण म्हणजे आम्ही अलीकडे पार्स केलेले FILTER.XML फंक्शन वापरून मजकूराचे XML मध्ये रूपांतर करून डायनॅमिकली विभाजित करणे आणि नंतर सेलद्वारे सेलचे विश्लेषण करणे. प्रत्येक वेळी या जटिल सूत्राचे व्यक्तिचलितपणे पुनरुत्पादन न करण्यासाठी, ते LAMBDA मध्ये गुंडाळणे आणि त्यावर आधारित डायनॅमिक श्रेणी तयार करणे सोपे होईल, म्हणजे एक नवीन कॉम्पॅक्ट आणि सोयीस्कर फंक्शन, त्याचे नाव देणे, उदाहरणार्थ, RAZDTEXT:

या फंक्शनचा पहिला युक्तिवाद स्त्रोत मजकूरासह सेल असेल आणि दुसरा - विभाजक वर्ण आणि तो परिणाम क्षैतिज डायनॅमिक अॅरेच्या स्वरूपात देईल. फंक्शन कोड खालीलप्रमाणे असेल:
=लॅम्ब्डा(t;d; ट्रान्सपोज(फिल्टर.एक्सएमएल(“
उदाहरणांची यादी अंतहीन आहे - कोणत्याही परिस्थितीत जिथे तुम्हाला एकच लांब आणि अवजड फॉर्म्युला प्रविष्ट करावा लागतो, LAMBDA फंक्शन जीवन लक्षणीयरीत्या सोपे करेल.
वर्णांची आवर्ती गणन
मागील सर्व उदाहरणांनी LAMBDA फंक्शनची फक्त एकच, सर्वात स्पष्ट बाजू दर्शविली आहे - दीर्घ सूत्रे गुंडाळण्यासाठी आणि त्यांचे इनपुट सुलभ करण्यासाठी "रॅपर" म्हणून त्याचा वापर. खरं तर, LAMBDA ची आणखी एक, खूप खोल, बाजू आहे जी ती जवळजवळ पूर्ण प्रोग्रामिंग भाषेत बदलते.
वस्तुस्थिती अशी आहे की LAMBDA फंक्शन्सचे मूलभूतपणे महत्त्वाचे वैशिष्ट्य म्हणजे त्यांची अंमलबजावणी करण्याची क्षमता पुनरावृत्ती - गणनेचे तर्क, जेव्हा गणनेच्या प्रक्रियेत फंक्शन स्वतःला कॉल करते. सवयीनुसार, ते भितीदायक वाटेल, परंतु प्रोग्रामिंगमध्ये, पुनरावृत्ती ही एक सामान्य गोष्ट आहे. अगदी व्हिज्युअल बेसिकमधील मॅक्रोमध्येही, तुम्ही ते अंमलात आणू शकता आणि आता, जसे तुम्ही पाहू शकता, ते एक्सेलमध्ये आले आहे. चला हे तंत्र व्यावहारिक उदाहरणासह समजून घेण्याचा प्रयत्न करूया.
समजा आपल्याला वापरकर्ता-परिभाषित फंक्शन तयार करायचे आहे जे स्त्रोत मजकूरातील सर्व वर्ण काढून टाकेल. अशा फंक्शनची उपयुक्तता, मला वाटते, तुम्हाला सिद्ध करण्याची गरज नाही – त्याच्या मदतीने कचरा टाकलेला इनपुट डेटा साफ करणे खूप सोयीचे असेल, बरोबर?
तथापि, मागील, पुनरावृत्ती नसलेल्या उदाहरणांच्या तुलनेत, दोन अडचणी आमच्या वाट पाहत आहेत.
- आमच्या फंक्शनचा कोड लिहिण्याआधी आम्हाला नाव द्यावे लागेल, कारण त्यामध्ये हे नाव फंक्शनला कॉल करण्यासाठी आधीच वापरले जाईल.
- सेलमध्ये असे रिकर्सिव्ह फंक्शन एंटर करणे आणि LAMBDA नंतर (आम्ही आधी केल्याप्रमाणे) कंसात वितर्क निर्दिष्ट करून डीबग करणे कार्य करणार नाही. तुम्हाला "स्क्रॅचमधून" मध्ये लगेच फंक्शन तयार करावे लागेल नाव व्यवस्थापक (नाव व्यवस्थापक).
चला आमच्या फंक्शनला कॉल करूया, म्हणा, CLEAN आणि आम्हाला दोन युक्तिवाद हवे आहेत - क्लीन करायचा मजकूर आणि मजकूर स्ट्रिंग म्हणून वगळलेल्या वर्णांची यादी:

टॅबवर आधी तयार केल्याप्रमाणे तयार करू सुत्र в नाव व्यवस्थापक नामांकित श्रेणी, त्यास CLEAR नाव द्या आणि फील्डमध्ये प्रविष्ट करा श्रेणी खालील बांधकाम:
=LAMBDA(t;d;IF(d="";t;CLEAR(SUBSTITUTE(t;LEFT(d);"");MID(d;2;255))))
येथे टी व्हेरिएबल हा मूळ मजकूर आहे जो साफ करायचा आहे आणि d हा हटवायचा असलेल्या वर्णांची सूची आहे.
हे सर्व असे कार्य करते:
पुनरावृत्ती 1
तुकडा SUBSTITUTE(t;LEFT(d);””), तुम्ही अंदाज लावू शकता, d या संचातील डाव्या वर्णातील पहिला वर्ण रिकाम्या मजकूर स्ट्रिंगसह t या स्त्रोत मजकुरात हटवायचा आहे, म्हणजे “ काढून टाकतो. अ”. मध्यवर्ती परिणाम म्हणून, आम्हाला मिळते:
Vsh zkz n 125 रूबल.
पुनरावृत्ती 2
नंतर फंक्शन स्वतःला कॉल करते आणि इनपुट म्हणून (पहिला वितर्क) मागील चरणात साफ केल्यानंतर जे उरले आहे ते प्राप्त करते आणि दुसरा युक्तिवाद पहिल्यापासून नाही तर दुसऱ्या वर्णापासून सुरू होणारी वगळलेल्या वर्णांची स्ट्रिंग आहे, म्हणजे “BVGDEEGZIKLMNOPRSTUFHTSCHSHSHCHYYYA. ," प्रारंभिक "A" शिवाय - हे MID फंक्शनद्वारे केले जाते. पूर्वीप्रमाणे, फंक्शन उरलेल्या (B) च्या डावीकडून पहिले वर्ण घेते आणि त्यास दिलेल्या मजकुरात (Zkz n 125 rubles) रिकाम्या स्ट्रिंगसह बदलते - आम्हाला मध्यवर्ती परिणाम मिळतो:
125 रु.
पुनरावृत्ती 3
फंक्शन स्वतःला पुन्हा कॉल करते, आधीच्या पुनरावृत्तीवर (Bsh zkz n 125 ru.) क्लिअर करण्यासाठी मजकूराचा काय शिल्लक आहे हे पहिले वितर्क म्हणून प्राप्त होते, आणि दुसरा युक्तिवाद म्हणून, वगळलेल्या वर्णांचा संच आणखी एका वर्णाने कापला जातो. डावीकडे, म्हणजे "VGDEEGZIKLMNOPRSTUFHTSCHSHSHCHYYYUYA." प्रारंभिक "B" शिवाय. मग ते पुन्हा या संचातून डावीकडून (B) पहिले वर्ण घेते आणि मजकूरातून काढून टाकते - आम्हाला मिळते:
sh zkz n 125 ru.
आणि असेच - मला आशा आहे की तुम्हाला कल्पना येईल. प्रत्येक पुनरावृत्तीसह, काढून टाकल्या जाणार्या वर्णांची सूची डावीकडे कापली जाईल आणि आम्ही शोधू आणि संचातून पुढील वर्ण शून्याने बदलू.
जेव्हा सर्व वर्ण संपतात, तेव्हा आपल्याला लूपमधून बाहेर पडावे लागेल - ही भूमिका फंक्शनद्वारे केली जाते IF (तर), ज्यामध्ये आमची रचना गुंडाळलेली आहे. (d=””) हटवण्याकरिता कोणतेही वर्ण शिल्लक नसल्यास, फंक्शनने यापुढे स्वतःला कॉल करू नये, परंतु केवळ क्लिअर करण्यासाठी मजकूर (व्हेरिएबल t) त्याच्या अंतिम स्वरूपात परत केला पाहिजे.
पेशींची आवर्ती पुनरावृत्ती
त्याचप्रमाणे, तुम्ही दिलेल्या श्रेणीतील सेलची पुनरावृत्ती गणनेची अंमलबजावणी करू शकता. समजा आपल्याला lambda नावाचे फंक्शन तयार करायचे आहे बदली यादी दिलेल्या संदर्भ सूचीनुसार स्त्रोत मजकूरातील तुकड्यांच्या घाऊक बदलीसाठी. परिणाम असे दिसले पाहिजे:

त्या. आमच्या कार्यात बदली यादी तीन युक्तिवाद असतील:
- प्रक्रियेसाठी मजकूर असलेला सेल (स्रोत पत्ता)
- लुकअपमधून शोधण्यासाठी मूल्यांसह स्तंभाचा पहिला सेल
- लुकअपमधील बदली मूल्यांसह स्तंभाचा पहिला सेल
फंक्शनने निर्देशिकेत वरपासून खालपर्यंत जावे आणि डाव्या स्तंभातील सर्व पर्याय क्रमशः बदलले पाहिजेत शोधण्यासाठी उजव्या स्तंभातील संबंधित पर्यायांकडे पर्याय. तुम्ही हे खालील रिकर्सिव लॅम्बडा फंक्शनसह अंमलात आणू शकता:

प्रत्येक पुनरावृत्तीवर शिफ्ट डाउन हे मानक एक्सेल फंक्शनद्वारे लागू केले जाते विल्हेवाट लावणे (ऑफसेट), ज्यामध्ये या प्रकरणात तीन युक्तिवाद आहेत - मूळ श्रेणी, रो शिफ्ट (1) आणि कॉलम शिफ्ट (0).
बरं, आपण निर्देशिकेच्या शेवटी पोहोचताच (n = “”), आपण पुनरावृत्ती समाप्त केली पाहिजे – आपण स्वतःला कॉल करणे थांबवू आणि स्त्रोत मजकूर व्हेरिएबल t मध्ये सर्व बदलीनंतर काय जमा झाले ते प्रदर्शित करू.
इतकंच. कोणतेही अवघड मॅक्रो किंवा पॉवर क्वेरी क्वेरी नाहीत - संपूर्ण कार्य एका फंक्शनद्वारे सोडवले जाते.
- एक्सेलची नवीन डायनॅमिक अॅरे फंक्शन्स कशी वापरायची: FILTER, SORT, UNIC
- SUBSTITUTE फंक्शनसह मजकूर बदलणे आणि साफ करणे
- VBA मध्ये मॅक्रो आणि वापरकर्ता-परिभाषित कार्ये (UDF) तयार करणे